Title: Improving Neural Fine-Grained Entity Typing with Knowledge Attention
Author: Ji Xin, Yankai Lin, Zhiyuan Liu, Maosong Sun
Link: http://nlp.csai.tsinghua.edu.cn/~lzy/publications/aaai2018_entitytyping.pdf
任务
本文针对的是Named Entity Typing(NET)任务,该任务主要是判断一个实体表示(entity mention)的类别,粒度的分类可以分为:person, location, organization,others。细粒度的分类根据不同的数据有着不同的分类情况,例如:FIGER dataset 有112类;也可以根据需要自定义类别个数进行分类,例如:从DBpedia中抽取22类。
该任务也是一个比较基础的任务,可以为问答,对话,语义理解等提供一些辅助理解的信息,而且和语义理解类似,同一个实体表示在不同的情境(context)下的类别是不一样,同样需要考虑情境信息。
现状
传统的方法大多集中在特征抽取,例如选取多种特征抽取的方法,例如pattern-based extractor,Knowledge base,mention-based extractor等,利用这些不同的方法得到实体表示的不同类别候选,然后利用词义消歧(word sense disambiguation )的方法选择最合适的类别。这里边最受关注的地方在于知识图谱的运用,知识图谱将很多先验知识及关系整合到图中,尤其是NET中的细粒度分类, 单纯利用神经网络来做是不行的,很多类别的样本都很少,而知识图谱可以提供必要的帮助。
神经网络的方法目前也慢慢多起来,神经网络在提取特征阶段已经被证明非常有效,因此在该任务上神经网络+知识图谱应该是一种非常有效的方法,而本文就是这样的一种方法。
模型
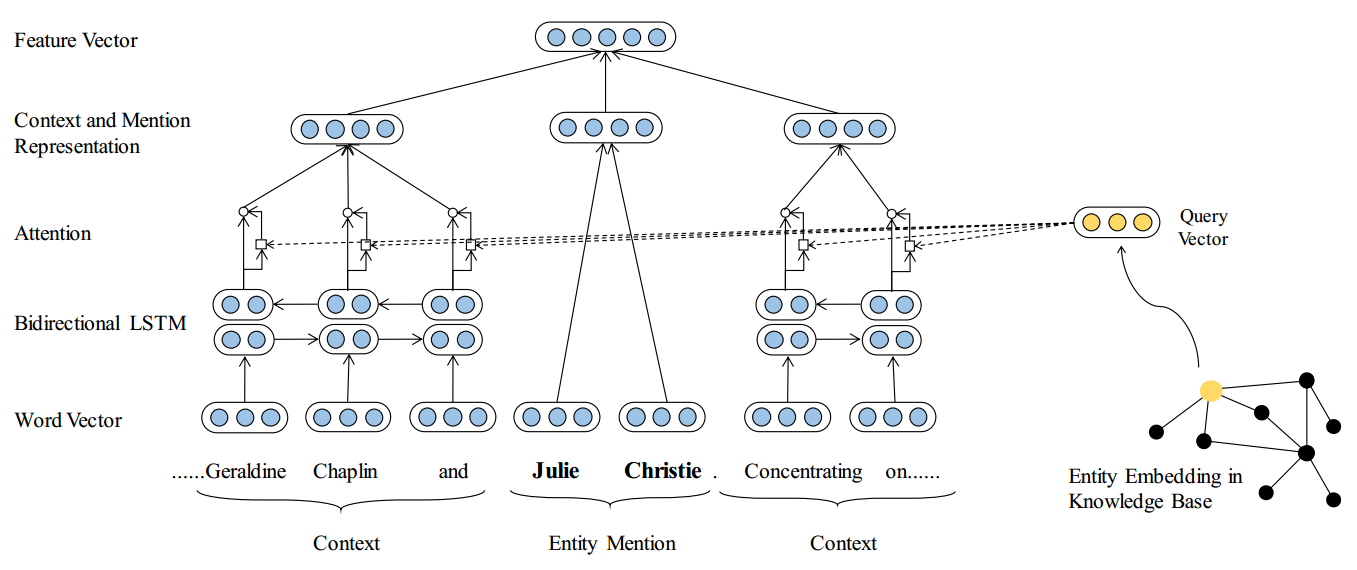
模型整体看起来是比较简单的,而本文主要是为了解决NET中的两个问题:
- 在实体表示分类时需要考虑其所存在的情境,而这点是被忽略的;
- 虽然知识图谱已经很早就被用到了NET中,但是知识图谱中实体之间的关系,并没有得到很好的利用。
因此,作者提出了如上的模型,具体如下:
首先适用预训练的模型对所有的词进行标识 ,得到每个词的词向量,
实体表示的向量表达
考虑到实体表示的短语是比较短的,大多是都是一个或者两个词,因此直接将每个词的向量相加,取均值,得到实体表示的向量表达:
$$m = \frac{1}{n_m}\sum_{i=1}^{n_m}m_i \quad \tag{1}$$
情境信息的表示
为了更好的表示中心词的情境,例如中心词所存在的句子,作者使用BiLSTM分别整合左边和右边的情境信息,并利用注意力机制整合他们在LSTM中的隐层状态,最后整合为一个情境表示向量:
$$c = \frac{\sum_{i=1}^{L}(a_i^l[\overrightarrow{h_i^l}, \overleftarrow{h_i^l}]+a_i^r[\overrightarrow{h_i^r}, \overleftarrow{h_i^r}]) }{\sum_{i=1}^{L}a_i^l+a_i^r} \quad \tag{2}$$
这个公式还是很好理解的,将每个状态的两个方向表示拼接起来,乘以对应的权重,然后做加权和,最后再做平均,就得到了情境信息的向量表示,那么接下来就是如何表示情境信息的权重了。
注意力机制
在这里作者考虑了很多不同的注意力机制,
语义注意力机制,就是考虑情境信息的权重,由自身的语义信息来计算所占的比重,类似于self-attention:
$$a_i^{SA} = \sigma(W_{s1}tanh(W_{s2}[\overrightarrow{h}_i, \overleftarrow{h}_i])). \quad \tag{3.1}$$
因为我们需要考虑的是实体表示的类别,那么也可以计算实体表示所关注的重点在什么地方,也就是基础版的attention:
$$a_i^{MA} = \sigma(mtanh(W_{MA}[\overrightarrow{h}_i, \overleftarrow{h}_i])). \quad \tag{3.2}$$
正如之前问题里提到的那样,知识图谱不仅包含了实体,同时还有实体之间的关系信息,这点也是十分重要的,因此作者使用了知识图谱中表示关系的方法TransE来处理知识图谱中的关系表示,并将其应用到注意力机制中:
$$a_i^{KA} = \sigma(etanh(W_{KA}[\overrightarrow{h}_i, \overleftarrow{h}_i])), \quad \tag{3.3}$$
这其中$e$就是实体的embedding表示,
类别预测
有了实体表示的向量和情境信息的向量,最后就是一个分类了,作者将得到的两个向量表示拼接起来,然后通过一个两层的MLP进行分类,得到最后的结果:
$$y = \sigma(W_{y1}tanh(W_{y2}[m, c])), \quad \tag{4}$$
最后使用二分类的交叉熵作为损失函数,因为每一个实体表示的类别可能不止一个,这可能是一个多分类问题,因此作者在每个类别上都是用了二分类的交叉熵,最后将所有的全都加起来作为最终的损失函数。
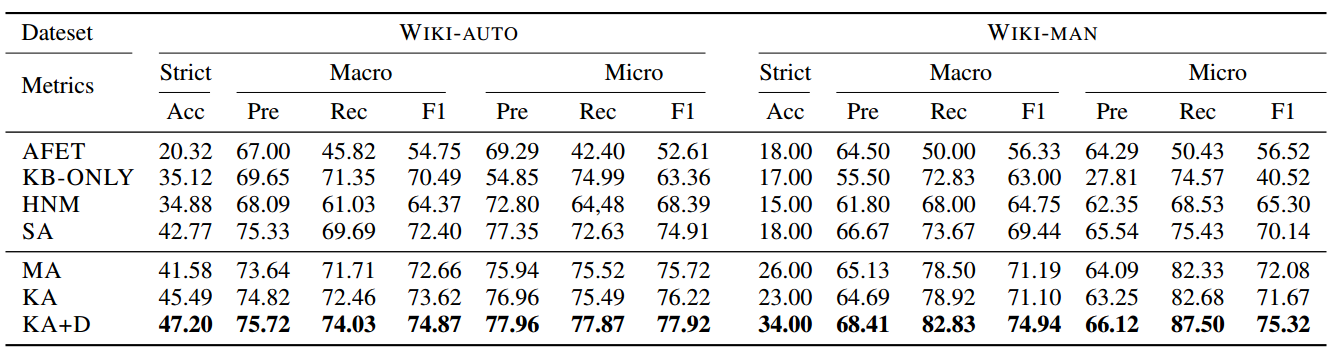
实验结果
照例,还是贴一个最后的结果图,因为使用了神经网络将情境信息融入到了实体分类中,可以更好地分类出在特定情境下的类别,也就更符合实际情况,从而获得更好的效果,当然将知识图谱中的关系信息也考虑进去也是本文的另一个创新点,这点还是很有意思的。
个人评价
这是我接触NET之后读的第一篇利用神经网络来做的方法,对比那些利用不同的特征抽取方法来对实体表示进行分类,神经网络在抽取特征方面确实是省了不少的力气,而且整个模型简单有效,这就是一种非常好的方法。当然,该方法相对来说还是比较简单的,例如在情境信息的表示,情境信息和知识图谱的融合,相互辅助等方面还有很多可以做的,而且这个问题对语义理解也是一个很重要的方面,很值得学习研究。
以上就是这篇文章的整体介绍,NET还是很有意思的,搞起来搞起来♪(^∀^●)ノ
